04 - Types de données et transformations
PRO1036 - Analyse de données scientifiques en R
October 6, 2025
Pourquoi ?

Tibbles
Les Tibbles sont des data frames modernes. Ils sont adaptés au tidyverse (en pratique, toutes les fonctions du tidyverse retournent des tibbles au lieu de data.frame).

- Les tibbles ont un affichage limité, adapté à la console
- Il est possible d’accéder à une colonne à l’aide des double crochets (
df[["x"]]) en plus du$(df$x). Il est ainsi possible d’utiliser le numéro de colonne au lieu du nom (df[[1]]) - Les tibbles fournissent également plus d’indications lorsque quelque chose ne va pas (messages de warnings).
Plotting
Au moment de faire un graphique, R va faire une conversion de type
Si on lui demande de plotter des catégories, il va créer des facteurs

Les facteurs sont ordonnées par ordre alphabétique par défaut
On peut manipuler les facteurs avec forcats

La grammaire de la manipulation de données
Basé sur des fonctions qui correspondent à des verbes permettant de manipuler des dataframes.
- Les facteurs sont utiles lorsque vous avez des données catégorielles et que vous voulez remplacer l’ordre des vecteurs de caractères pour améliorer l’affichage
- Le package forcats fournit une suite d’outils utiles qui résolvent des problèmes courants avec les facteurs
Exemple: starwars

Ordre selon la fréquence : fct_infreq()

Regroupement de facteurs
Regardons maintenant la masse moyenne selon la couleur des yeux:

Regroupement et changement d’ordre !
Nous allons maintenant regrouper les couleurs des yeux et les ordonner selon la masse moyenne

Exemple: Hotels

Exemple: Hotels

Renommer les niveaux : fct_recode()
Si on veut simplement renommer les niveaux, on peut utiliser fct_recode()

Dates

lubridate est un package tidyverse-friendly qui facilite la manipulation des dates
Il ne fait pas partie du coeur tidyverse, donc il doit être installé avec
install.packages("lubridate")mais il n’est pas chargé avec lui, et doit être explicitement chargé aveclibrary(lubridate).- …
Étape 4 - Visualiser

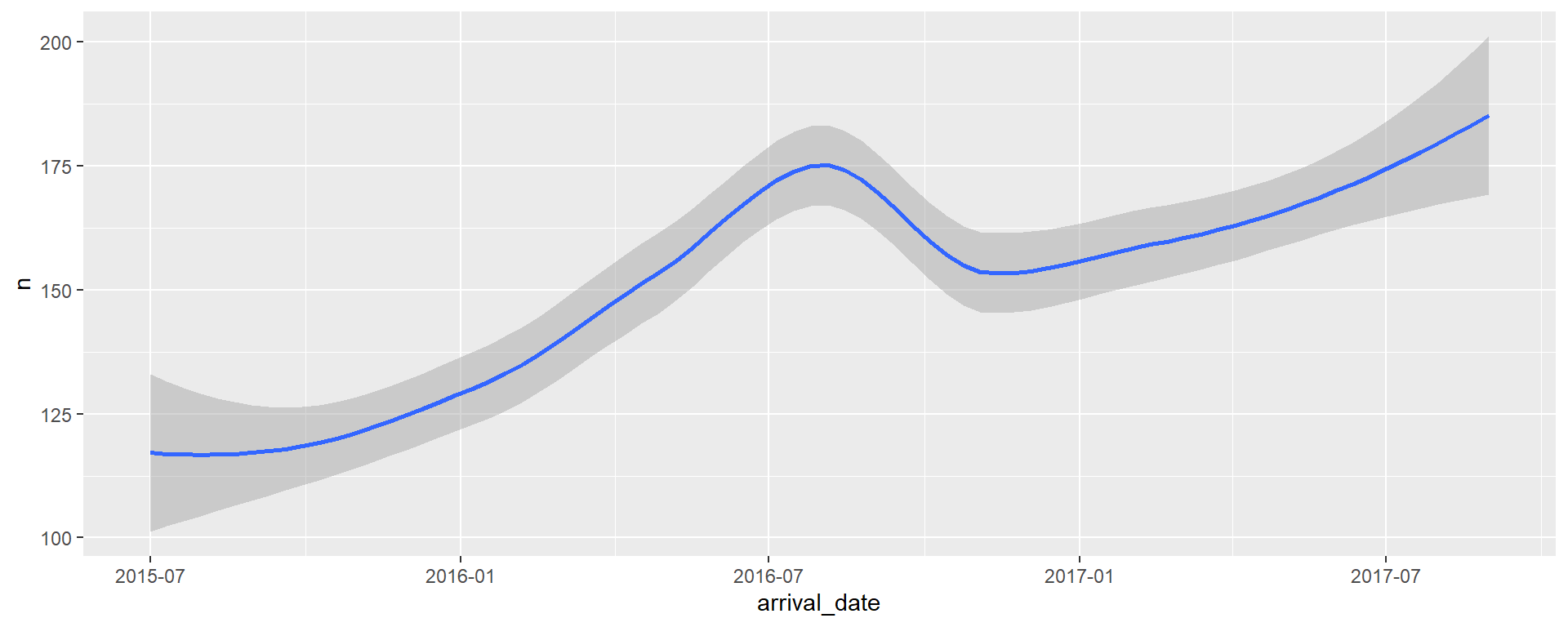
Quel est le problème ici ?
Étape 3a - Visualiser

Étape 3b - Visualiser avec une courbe
hotels %>%
mutate(arrival_date = ymd(glue("{arrival_date_year} {arrival_date_month} {arrival_date_day_of_month}"))) %>%
count(arrival_date) %>%
ggplot(aes(x = arrival_date, y = n, group = 1)) +
geom_smooth() #<<